ブログ三日坊主になりつつあるので近況報告でも・・・
グラボを買った。
![IMG_7006[1]](http://kentaroid.com/wp-content/uploads/2013/04/IMG_70061.jpg)
Windwowsエクスペリエンス。グラボ最高点。
SSDがボトルネック。
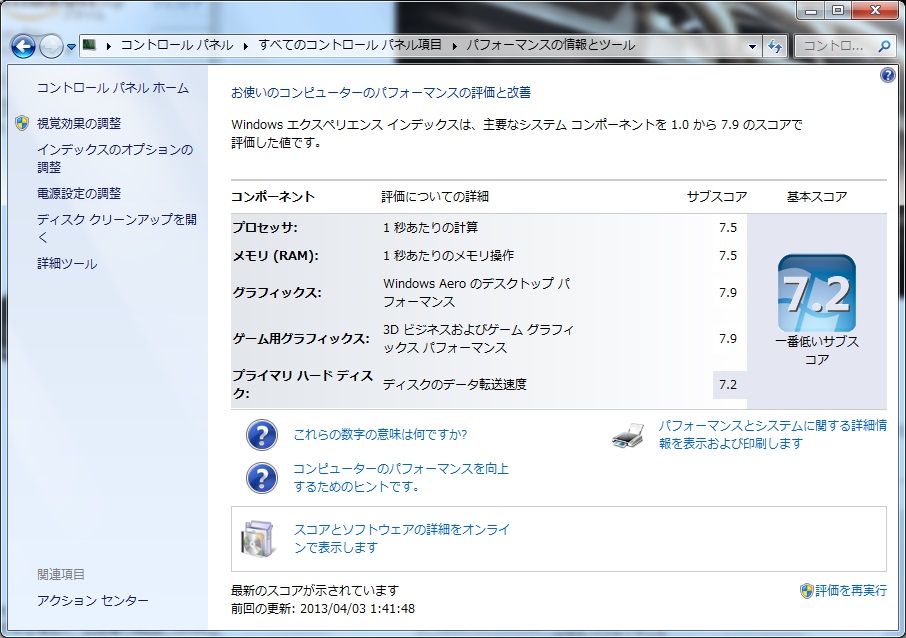
いいわこれ。
けっきょくのところハード更新すんのもひとつの解決策です。
色々遊べそう。ブフフ
ブログ三日坊主になりつつあるので近況報告でも・・・
グラボを買った。
Windwowsエクスペリエンス。グラボ最高点。
SSDがボトルネック。
いいわこれ。
けっきょくのところハード更新すんのもひとつの解決策です。
色々遊べそう。ブフフ
会社でのお仕事。PrimeSense x Openframeworks で作ってる。
体の動きにあわせて文字が動く。みたいな。

これ系のセンサーについてはこの一年かなり使い倒したなー。Kinectも。感覚的には、OpenNIよりWindowsSDKのほうが扱いやすいし安定感はある。でも使えるのはやっぱOpenNIだ。スケルトンの認識数で有利だし、ハードがごつくない。IRカメラは開発元同じっぽい(?)けどASUSのXTIONはKinectよりもRGBが綺麗だと思う。(kinectはなぜか標準でジャギが目立つ)
このセンサー認識精度も優秀なんだけど、こういう展示作品にする場合、プレイヤーの後ろに人だかりができてしまって、プレイヤーまで認識精度が落ちる。というのは、認識のトリガーのようなものはあくまで動きなので、カメラ的に背景が動いてるとやっぱ認識が悪くなる。一回精度が落ち始めるとなかなか復活しない。なのでセンサーを定期的にリセットしたいのだけど、そういうAPIがなかった。センサーを完全にシャットダウンすることはできるけど、時間がかかりすぎる。
で、今回OPENNI2+NITE2 という構成に載せ替えてみた。ofxアドオンになかったので、主要処理はサンプルから移植。NITE2ではのUserTrackerをいったん破棄して再構築することでセンサーのリセットが可能になってた。この場合のリセットは2秒ぐらいかかる。
で、様子をみてるけどnite2.dllがたまにエラーを吐いて落ちる見たい。悩ましいなー。
画像処理の高速化はshaderでやれというツッコミは置いておいて、(shaderでは色はそもそもfloat値なので関係ない。)unsigned char – float変換はよく使うし、出現頻度が多い。これは精度の都合で 0-255(8bit)を0.0f-1.0fとしてfloat精度で取り扱うことで画質ロスを無くし、かつ高速なfloat演算にあやかるというもの。で、今回は1.0f/255.0f-255.0f/255.0fの計算結果を配列にしておいてunsigned charをインデックスにして取得したら高速になるんじゃない?っていう仮説。あんま意味ないのでこのエントリーは読まないほうがいいwww
いわゆる下記のようなケース
この時点で掛算しか使ってないので、意味無さそうだよな・・・。
単純に掛算VS配列の結果呼び出しっていうテストになってる。
//byte から float unsigned char b=128; float f=b*0.003921568627451f; // *1.0f/255.0f
適当に配列を用意し、constで計算しておく。
一応if分岐しまくるfloat2Byteも作ったけど面倒なので貼らない。
#pragma once
class KCast
{
public:
static float b2Float(unsigned char in);
static unsigned char f2Byte(float in);
static const float b2fMap[256];
};
const float KCast::b2fMap[256]={
0.0f/255.0f,1.0f/255.0f,2.0f/255.0f,3.0f/255.0f,4.0f/255.0f,
5.0f/255.0f,6.0f/255.0f,7.0f/255.0f,8.0f/255.0f,9.0f/255.0f,
10.0f/255.0f,11.0f/255.0f,12.0f/255.0f,13.0f/255.0f,14.0f/255.0f,
15.0f/255.0f,16.0f/255.0f,17.0f/255.0f,18.0f/255.0f,19.0f/255.0f,
20.0f/255.0f,21.0f/255.0f,22.0f/255.0f,23.0f/255.0f,24.0f/255.0f,
25.0f/255.0f,26.0f/255.0f,27.0f/255.0f,28.0f/255.0f,29.0f/255.0f,
30.0f/255.0f,31.0f/255.0f,32.0f/255.0f,33.0f/255.0f,34.0f/255.0f,
35.0f/255.0f,36.0f/255.0f,37.0f/255.0f,38.0f/255.0f,39.0f/255.0f,
40.0f/255.0f,41.0f/255.0f,42.0f/255.0f,43.0f/255.0f,44.0f/255.0f,
45.0f/255.0f,46.0f/255.0f,47.0f/255.0f,48.0f/255.0f,49.0f/255.0f,
50.0f/255.0f,51.0f/255.0f,52.0f/255.0f,53.0f/255.0f,54.0f/255.0f,
55.0f/255.0f,56.0f/255.0f,57.0f/255.0f,58.0f/255.0f,59.0f/255.0f,
60.0f/255.0f,61.0f/255.0f,62.0f/255.0f,63.0f/255.0f,64.0f/255.0f,
65.0f/255.0f,66.0f/255.0f,67.0f/255.0f,68.0f/255.0f,69.0f/255.0f,
70.0f/255.0f,71.0f/255.0f,72.0f/255.0f,73.0f/255.0f,74.0f/255.0f,
75.0f/255.0f,76.0f/255.0f,77.0f/255.0f,78.0f/255.0f,79.0f/255.0f,
80.0f/255.0f,81.0f/255.0f,82.0f/255.0f,83.0f/255.0f,84.0f/255.0f,
85.0f/255.0f,86.0f/255.0f,87.0f/255.0f,88.0f/255.0f,89.0f/255.0f,
90.0f/255.0f,91.0f/255.0f,92.0f/255.0f,93.0f/255.0f,94.0f/255.0f,
95.0f/255.0f,96.0f/255.0f,97.0f/255.0f,98.0f/255.0f,99.0f/255.0f,
100.0f/255.0f,101.0f/255.0f,102.0f/255.0f,103.0f/255.0f,104.0f/255.0f,
105.0f/255.0f,106.0f/255.0f,107.0f/255.0f,108.0f/255.0f,109.0f/255.0f,
110.0f/255.0f,111.0f/255.0f,112.0f/255.0f,113.0f/255.0f,114.0f/255.0f,
115.0f/255.0f,116.0f/255.0f,117.0f/255.0f,118.0f/255.0f,119.0f/255.0f,
120.0f/255.0f,121.0f/255.0f,122.0f/255.0f,123.0f/255.0f,124.0f/255.0f,
125.0f/255.0f,126.0f/255.0f,127.0f/255.0f,128.0f/255.0f,129.0f/255.0f,
130.0f/255.0f,131.0f/255.0f,132.0f/255.0f,133.0f/255.0f,134.0f/255.0f,
135.0f/255.0f,136.0f/255.0f,137.0f/255.0f,138.0f/255.0f,139.0f/255.0f,
140.0f/255.0f,141.0f/255.0f,142.0f/255.0f,143.0f/255.0f,144.0f/255.0f,
145.0f/255.0f,146.0f/255.0f,147.0f/255.0f,148.0f/255.0f,149.0f/255.0f,
150.0f/255.0f,151.0f/255.0f,152.0f/255.0f,153.0f/255.0f,154.0f/255.0f,
155.0f/255.0f,156.0f/255.0f,157.0f/255.0f,158.0f/255.0f,159.0f/255.0f,
160.0f/255.0f,161.0f/255.0f,162.0f/255.0f,163.0f/255.0f,164.0f/255.0f,
165.0f/255.0f,166.0f/255.0f,167.0f/255.0f,168.0f/255.0f,169.0f/255.0f,
170.0f/255.0f,171.0f/255.0f,172.0f/255.0f,173.0f/255.0f,174.0f/255.0f,
175.0f/255.0f,176.0f/255.0f,177.0f/255.0f,178.0f/255.0f,179.0f/255.0f,
180.0f/255.0f,181.0f/255.0f,182.0f/255.0f,183.0f/255.0f,184.0f/255.0f,
185.0f/255.0f,186.0f/255.0f,187.0f/255.0f,188.0f/255.0f,189.0f/255.0f,
190.0f/255.0f,191.0f/255.0f,192.0f/255.0f,193.0f/255.0f,194.0f/255.0f,
195.0f/255.0f,196.0f/255.0f,197.0f/255.0f,198.0f/255.0f,199.0f/255.0f,
200.0f/255.0f,201.0f/255.0f,202.0f/255.0f,203.0f/255.0f,204.0f/255.0f,
205.0f/255.0f,206.0f/255.0f,207.0f/255.0f,208.0f/255.0f,209.0f/255.0f,
210.0f/255.0f,211.0f/255.0f,212.0f/255.0f,213.0f/255.0f,214.0f/255.0f,
215.0f/255.0f,216.0f/255.0f,217.0f/255.0f,218.0f/255.0f,219.0f/255.0f,
220.0f/255.0f,221.0f/255.0f,222.0f/255.0f,223.0f/255.0f,224.0f/255.0f,
225.0f/255.0f,226.0f/255.0f,227.0f/255.0f,228.0f/255.0f,229.0f/255.0f,
230.0f/255.0f,231.0f/255.0f,232.0f/255.0f,233.0f/255.0f,234.0f/255.0f,
235.0f/255.0f,236.0f/255.0f,237.0f/255.0f,238.0f/255.0f,239.0f/255.0f,
240.0f/255.0f,241.0f/255.0f,242.0f/255.0f,243.0f/255.0f,244.0f/255.0f,
245.0f/255.0f,246.0f/255.0f,247.0f/255.0f,248.0f/255.0f,249.0f/255.0f,
250.0f/255.0f,251.0f/255.0f,252.0f/255.0f,253.0f/255.0f,254.0f/255.0f,
255.0f/255.0f
};
float KCast::b2Float(unsigned char in){
return *(b2fMap+in);
}
実験。
適当にたして割るだけのループ。関数キャストと普通の掛算による計算を各10回ずつ。
関数のオーバヘッドもありそうなのでメモリを直接読むテストも加える。
int main(){
const float div=1.0f/255.0f;
unsigned long long start;
float res;
unsigned char i;
puts("start");
for(int x=0;x<10;x++){
//キャスト関数で処理
start= ofGetSystemTime( );
res=0.0f;
for (int m=0;m<1000000;m++){
i=0;
while (i<254){
res+=KCast::b2Float(i);
i++;
}
res*=div;
}
printf("キャスト TIME=%llu:RESULT=%e\n",ofGetSystemTime( )-start,res);
//直接メモリ読む
start= ofGetSystemTime( );
res=0.0f;
for (int m=0;m<1000000;m++){
i=0;
while (i<254){
res+=*(KCast::b2fMap+i);
i++;
}
res*=div;
}
printf("直接メモリ TIME=%llu:RESULT=%e\n",ofGetSystemTime( )-start,res);
//掛算のみ
start= ofGetSystemTime( );
res=0.0f;
for (int m=0;m<1000000;m++){
i=0;
while (i<254){
res+=i*div;
i++;
}
res*=div;
}
printf("かけざん TIME=%llu:RESULT=%e\n",ofGetSystemTime( )-start,res);
}
return 1;
}
結果
start
キャスト TIME=2459:RESULT=4.960788e-001
直接メモリ TIME=729:RESULT=4.960788e-001
かけざん TIME=724:RESULT=4.960788e-001
キャスト TIME=2435:RESULT=4.960788e-001
直接メモリ TIME=722:RESULT=4.960788e-001
かけざん TIME=716:RESULT=4.960788e-001
キャスト TIME=2396:RESULT=4.960788e-001
直接メモリ TIME=721:RESULT=4.960788e-001
かけざん TIME=747:RESULT=4.960788e-001
キャスト TIME=2419:RESULT=4.960788e-001
直接メモリ TIME=718:RESULT=4.960788e-001
かけざん TIME=716:RESULT=4.960788e-001
キャスト TIME=2398:RESULT=4.960788e-001
直接メモリ TIME=717:RESULT=4.960788e-001
かけざん TIME=718:RESULT=4.960788e-001
キャスト TIME=2395:RESULT=4.960788e-001
直接メモリ TIME=716:RESULT=4.960788e-001
かけざん TIME=718:RESULT=4.960788e-001
キャスト TIME=2403:RESULT=4.960788e-001
直接メモリ TIME=726:RESULT=4.960788e-001
かけざん TIME=721:RESULT=4.960788e-001
キャスト TIME=2411:RESULT=4.960788e-001
直接メモリ TIME=717:RESULT=4.960788e-001
かけざん TIME=715:RESULT=4.960788e-001
キャスト TIME=2397:RESULT=4.960788e-001
直接メモリ TIME=717:RESULT=4.960788e-001
かけざん TIME=720:RESULT=4.960788e-001
キャスト TIME=2395:RESULT=4.960788e-001
直接メモリ TIME=715:RESULT=4.960788e-001
かけざん TIME=717:RESULT=4.960788e-001
トリプルスコアで完敗www
結論 :
掛算は早いから計算したほうがよっぽど良い。まず関数のオーバーヘッドは大きい印象。inlineとかでこのへん少しは改善できるのかな。メモリ読み込みも検討しているけど、そもそもポインタのリードは遅い。このテストでは1-255まで順に読ませているけど連続するメモリ読み出しはかなり高速になるので、ランダムにアクセスされた場合はほぼ使えないと考えられる。
まぁ、こういう実験するとポインタ呼び出しの速度とか、身にしみて覚えるからいいよっていう話でした。
m9(^Д^)プギャー
進まない。ハマり気味です・・・。
マトリクス演算のクラスって便利だけど、種類が多い。
4×4のマトリクスだと、OpenGLではGlfloat[16]で始まり、assimp(3Dモデルローダライブラリ)ではaiMatrix4x4,bullet(物理演算ライブラリ)ではbtTransform。ちなみにopenFrameworksではofMatrix4x4となる。各ライブラリが独自の実装を行なっているから面倒なんだけど、回転移動スケーリング、算術オペレータなど、同じ機能があって同じ使い方ができる。色々使う場合、相互変換がちゃんとできないと困るので、下記にまとめておく。
とにかくGLfloat[16] をベースに変換していけば分かりやすい。内部的に何らかのかたちで4×4で値を保持しているわけだが、OpenGLのマトリクスをtransposeしないと使えないケースが多いので注意が必要。assimpやmascotcapsleなどもtransposeが必要だった。
まず、OpenGLの現在の状態を得る場合下記のようにする。
GLfloat m[16]; glGetFloatv(GL_MODELVIEW_MATRIX, m);
assimpに変換Transposeが必要。a1-d4の並びに注意
aiMatrix4x4 aim= aiMatrix4x4(m[0], m[1], m[2], m[3], m[4], m[5], m[6], m[7], m[8], m[9], m[10], m[11], m[12],m[13], m[14],m[15]); aim.Transpose();
もしくは
aiMatrix4x4 aim= aiMatrix4x4(m[0], m[4], m[8], m[12], m[1], m[5], m[9], m[13], m[2], m[6], m[10], m[14], m[3],m[7], m[11],m[15]);
bulletに変換。関数があるので楽勝
btTransform btm; btm.setFromOpenGLMatrix(m);
逆の場合。
assimpからGLfloat[16]
m[0]=aim.a1; m[1]=aim.b1; m[2]=aim.c1; m[3]=aim.d1; m[4]=aim.a2; m[5]=aim.b2; m[6]=aim.c2; m[7]=aim.d2; m[8]=aim.a3; m[9]=aim.b3; m[10]=aim.c3; m[11]=aim.d3; m[12]=aim.a4; m[13]=aim.b4; m[14]=aim.c4; m[15]=aim.d4;
bulletからGLfloat[16]
btm.getOpenGLMatrix(m);
でもってOpenGlに適用する。
glPushMatrix(); glMultMatrixf(m); /*描画*/ glPopMatrix();
これでbtTransformからのaiMatrix4x4とか、自由自在にできる。
3Dでスプライン曲線を描きたいというお題。
いいサンプルが見つからなかったので、とりあえずofx3DSplineをつくってみた。基本的には頂点配列を更新するとスプライン描画用頂点配列を更新してくれるクラス。でも、重かった。60fpsだと256頂点で20分割の補完が限界。これはリアルタイムに曲線をアニメーションさせ続けた場合の負荷。描画はVBOで高速にやってるのでCPUでやってるスプラインの計算がイケてないことは間違いない。他にもいろいろ計算させたいのでこれでは使い物にならない。

そこで、最近ハマってるシェーダーの登場。今回はあまり使ったことのないGeometryシェーダを使ってみる。ちなみにスプラインをやりたいのにB−スプライン曲線になってるのは力不足のため。本当にやりたいのは指定点を必ず通過するほうのスプライン曲線。こちらのほうがアニメーションでは制御しやすそうな気がしてる。あとこの分割ってところはTessellation シェーダーの役割のような気がしていて、実際できるみたいなんだけど、情報が少なかったのとATIとNvidiaで違うところがあるらしいので、今回はGeometryで。
スプラインの参考にしたのはこのドキュメント。
以下、GLSL4でB-スプラインを描くジオメトリシェーダー。uniformで頂点の分割数を変更可能。
layout( lines_adjacency ) in;
layout( line_strip, max_vertices=200 ) out;
uniform int division;
vec4 w_bspline(float alpha){
vec4 tmp;
float a2=alpha*alpha;
float a3=alpha*alpha*alpha;
tmp.x = -a3 + 3.0*a2 - 3.0*alpha + 1.0;
tmp.y = 3.0*a3 - 6.0*a2 + 4.0;
tmp.z = -3.0*a3 + 3.0*a2 + 3.0*alpha + 1.0;
tmp.w = a3;
return tmp;
}
void main(void)
{
int i;
vec4 w;
for (i=0; i<=division; i++)
{
w = w_bspline(float(i)/float(division));
gl_Position.xyzw =
w.x * gl_PositionIn[0].xyzw +
w.y * gl_PositionIn[1].xyzw +
w.z * gl_PositionIn[2].xyzw +
w.w * gl_PositionIn[3].xyzw;
EmitVertex();
}
}
注意点はOPENGLのほうで、GL_LINE_STRIP_ADJACENCYを指定すること、これによってシェーダーが隣接含め4点を受け取り補完を行える。こんなかんじで。
glEnableClientState(GL_VERTEX_ARRAY); glVertexPointer(3, GL_FLOAT, 0, mSplineVtx); glDrawArrays(GL_LINE_STRIP_ADJACENCY,0,mSplineVtxNum); glDisableClientState(GL_VERTEX_ARRAY);
ちなみにopenframeworksのofShaderはジオメトリシェーダーにもちゃんと対応してて、以下のように読み込めるようになってた。Tessellation はいまのところ未対応。
shader.load("myShader.vert","myShader.frag","myShader.geom");
以上でベジェ曲線の描画は上手く行ったんだけど、やっぱり重かったw。CPUでやるのとパフォーマンスそんなに変わってない。やはり若干滑らかさを犠牲にするしか無いかな。そもそもB-スプラインじゃだめだしw
参考:
ソフトボディをやってみたかったので、とりあえ本買ってみた。
この本、泣けるぐらいSoftBodyの解説は少なかったわ( 3ページぐらい)w
けど、モデル(wavefront*.obj)のメッシュからsoftbody生成するサンプルがあった。まぁbulletライブラリのサンプルでもsoftbodyのサンプルいくつかあるんだけどね・・・。この本のサンプルはCode::Blocks+MinGWという構成だが、とりあえずVisualStudioで動かしてみた。

なんか表示は上手く行ってないっぽかったけど、上は柔軟体と鋼体のteapot。ぐにゃぐにゃしてる。(っぽい)
softbodyを使うためにはいつも使ってるbtDiscreteDynamicsWorld じゃなくて btSoftRigidDynamicsWorldを使う。当然RigidBodyも使えるワールドだが、softの計算もやるのでパフォーマンスをちょっと心配したけど、軽く試したところRigidについてはそんなに悪くなさそうだった。が、物体をすり抜けてしまうことが多い気がした。通常の物理演算が鋼体の衝突で実現されているのに対してこっちはMeshで頂点の当たり判定を細かくやってるイメージ。ただし、softbodyのオブジェクトの自分自身の当たり判定はほとんど突き抜けてしまっているので、判定が無いか、甘い印象。
で、いつもどおりopenframeworksで使ってみたかったので、ofxBulletで移植を始めたんだけど例のごとく先駆者がいらっしゃいました。
https://github.com/damiannz/ofxBullet/
このライブラリではassimpでロードしたメッシュをもとにsoftbodyを作るとことまでやってくれる。とてもいい。

手前のteapodがぐにゃんぐにゃんしてる。やっぱsoftbodyは突き抜けがおおい。このアドオンの調整も色々必要になりそう。あとはこれを動かしたいわけだけど、ノードがわかれば鋼体と同じ要領で特定の頂点に対して力を加えることができるようだ。
softbody ->addForce(const btVector3& forceVector,int node);
パフォーマンスは少し心配。teapotだと、最近のマシンでも10個も入れるとFPSが結構落ちてくる。あと、柔軟体をワールドに投下するタイミングでも、頂点が多いからか一瞬固まってしまうのも気になる。動きは60FPSでてれば結構気持ちがいい。なんか楽しいことはできそうだ。
やってる途中でofxslitscanというopenFrameworks用のslitscanアドオンが見つかった。
http://jamesgeorge.org/ofxslitscan/
なんか想像してたのと違う実装方法があるっぽい。ひとまずソース読ませていただこう思う。
とりあえず、以前のエントリで書いた方法でリアルタイムのスリットスキャン実装をやってみた。
https://github.com/kentaroid/ofVideoSlitScan

うねうね動きます。
プログラムでは下記の変更ができる。
・スリットの数の調整
・スリット間のSmoothing強度(0~1)
・ミラーモード
・スキャン方向のきりかえ、(Up|Down)
・フルスクリーン表示
実際やってみてわかったのは、Smoothingのためにちょっとだけアルファ合成してもぜんぜんきれいにつながらないということ。もっと合成の方法を工夫しなければだめっぽいぞ・・・。
最近は勉強のためにofxBulletじゃなくて直bulletもやってるよー。
ちょっと前に会社のWorksでopenframework+ofxBullet+OpenNIみたいなインスタレーションを作った。その時にこの素敵addonがWindowsに対応していなくて困った。MacのSTBとかありえないし、LINUXはパフォーマンスが不安だし。とりあえずWindowsへの導入やってみたら、思ったより普通にできた。
せっかくなので、すでにありそうな気がするけど、改めて最新のbullet(2.81-rev2613)でビルドしなおして、サンプルのsln(vs2010)も作った。巷で話題のGitHubとかいうものを使ってみたかったのでこちらで公開しておきます。
https://github.com/kentaroid/ofxBullet

以下、簡単に手順をメモ。
1.bulletをwindowsでビルド
http://code.google.com/p/bullet/downloads/list から最新ソースをダウンロードしてVisualStudioでコンパイル。
2. NickHardeman/ofxBullet をfork
forkしてみたかったんです。ofxBulletのlibフォルダの所定の位置に生成された*.libとかsrcをコピー。これでライブラリの設定はほぼ完了。ただしMacとlinuxの bulletライブラリのリビジョンは違ってるので、ライブラリもコンパイルしなおさないと多分動かなくなる。その場合は元のやつ使ったら良いです。
3. サンプルのビルド
ofxBulletのサンプルの main.cpp,testApp.h,testApp.cpp を使ってopenFrameworksプロジェクトを作成。アドオンソースとかリンカにパスを通しまくる。debugも、releaseも。これが毎度のこと面倒である・・・。いい方法ないのかっていつも思うけど、最近ではライブラリ作った人に感謝しながらこの作業を行うことにしてる。(あなたのおかげでぼくはこんなたんじゅんなさぎょうでこのきのうをつかうことができますありがとうございます。) なんかマクロとかで上手くやってる人がいるらしいよ・・・。
4. ちょっとしたfix
addon、サンプルともに少しのエラーを吐く。
・キャスト方法を明示。 static_cast -> const_cast
・ちょくちょく出てくる引数の btTransform を明示的に参照渡し。
なんだかMacでみた時と色(light)が違う気がするけど一応動いてる。ちなみに一箇所バグがあって、joint使うとアプリの終了時にAssertionされる。これは終了時に物体だけ破棄されるのにjointが開放されてないとかが原因だった気がする。前使った時は終了時にちゃんとjointでつながった物体をdeleteする前にjointをdeleteするみたいな処理をがっつり書いたら落ちなくなった。この辺も時間があれば見なおしておきます。
フォントで写真やイラストを再構成する画像処理プログラム。2年前にiOSアプリとして作ったものだが、アプリとしては重すぎるのでストアには公開できなかった・・・。
このプログラムでは様々なFONTや、単色のイラスト(マーク)などで写真を構築できる。画像処理としてはそれほど複雑なものではなく、単純にピクセルのテスト・アップデートの繰り返しである。ただしテスト・描画用のメモリを別にもつなど、高速化の工夫はいくつかやっている。あとはマルチスレッドとランダムアクセスをやればかなり早くなると思う。
アニメーションは画像処理のプロセスを単純に時間軸にそって出力した結果である。このままだと単調でつまんないのでインスタレーションとして再構築しようと思ってる。レンダリングマップをDBに保存して3D空間で一つ一つの文字を動かすみたいな。


スリットスキャンの静止画が撮れるアプリをiPhoneで作ってみたけど、やっぱ動画じゃないと面白くなかった。今回はPCのカメラ画像でリアルタイムにやっみようと思う。
スリットスキャンてこんなやつ。
Slit Scan from Stephen Boehnemann on Vimeo.
以下は、プログラム作成のためのメモ。
スリットスキャンを実装する場合、時間差で過去フレームを再生するわけだから、おそらくスリット数分のフレームを保存して置かなければならない。スリットの数Nとした場合、最低限確保が必要なメモリは下記の通り。
sizeof(unsigned char)*N*3*width*height
仮に、ソースサイズが1024×768で200スリットとすると、
200*3*1024*768 =471,859,200byte=450Mbyte
最近のPCは8Gぐらい普通に積んでるから1Gぐらい使うようなアプリでもいけるのかな?
問題になりそうなのは結果画像の生成速度。各フレームのリード自体は画像一枚分だから、そこまで重くないのかもしれない。スリットの動き・形状もいろいろ考えられるけど、リアルタイム処理の場合は上から下、または下から上ならピクセル配列的にも高速に処理できそうだ。
スリット幅が1pxを超えると、おそらくフレーム間のズレが目立つため理想はN=heightなのかな。その場合メモリは1.68GByte、 スレッドの遅延は768/30fpsで20秒以上かかってしまうことになる。ちょっと遅すぎるしメモリも絶望的だなぁ。とりあえずスリットの幅を広げてフレーム間をアルファ合成する方法でやってみようと思う。あとはカメラが30のFPS出ないようであればフレーム間がガタガタになってしまいそう。
この辺りの落とし所は探りながら。相当パワーのあるマシンが必要になりそうだ。
実装は次回。