久しぶりにOpenMPをやってみたのでメモ。GPUシェーダ、CUDAとか使ってみてるけど、OpenMPが一番簡単にできる並列コンピューティングの環境だなと。でもCUDAは体感がすごかったけどOpenMPではイマイチ早くなった気がしないよ。最適化が不十分なんだろうけど。
使い方のメモ。*VS2010
構成プロパティのC/C++、[言語]のなかのOpenMPサポート有効にする
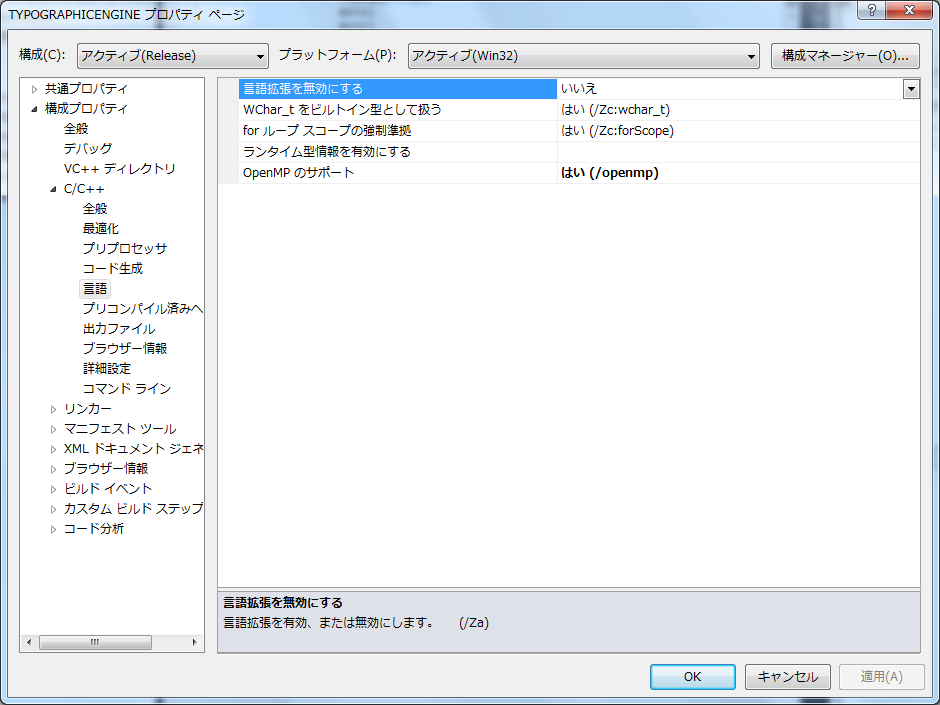
ヘッダインクルード
#include <omp.h>
ソース多分こんなかんじになった。
ピクセル内部で何かを探す処理。Y移動を並列化するやつを抜粋。
int y;
const size_t height= 1024*2;
const size_t width = 1024*2;
bool founded=false;
#ifdef _OPENMP
omp_lock_t myLock;
omp_init_lock(&myLock);
#pragma omp parallel for
#endif
for (y=0;y<height;y++) {
int x;
float rf,gf,bf;
bool flg;
for (x=0;x<width&&!founded;x++) {
//処理
if(発見)founded= true;
}
#ifdef _OPENMP
omp_set_lock(&myLock);
#endif
if(!founded){
founded=true;
#ifdef _OPENMP
printf(" [OMP:%i]", omp_get_thread_num());
#endif
}
#ifdef _OPENMP
omp_unset_lock(&myLock);
#endif
}
ソースの改修が少ないまま並列化できるのがメリット。並列スレッド数は多分最近のPCでも8とかだからCPUコア数依存かな?。色々試したところ、上記のようにループサイズが小さいとあまり効果がない気がした。割と処理大きめに並列化したほうが良さげだと感じてる。今回の並列で検索するロジックはどこかで見つかった場合処理を終了させるため、見つからないスレッドが破棄され無意味になっている。それぞれで別検索を行わせて各スレッドに結果が出せるように組んだほうが良いと思った。何ゆってるかわからないけどそういうことだと思う。あと、
・ループ外側で定義する変数は共通化されるので定義する場所に注意。
・共用変数の変更はロックが使える。
・goto,breakは内部では使えるけど、脱出はできない。
なんかそれ専用のコマンドがあるっぽい。
・Forの終了条件は確実性が求められる。
丁寧にコーディングすればあまり間違いがおこならいので、ちょっとした並列化には効果ありそう。次回は色々ベンチマークとって効果的な書き方を検証していこうと思う。
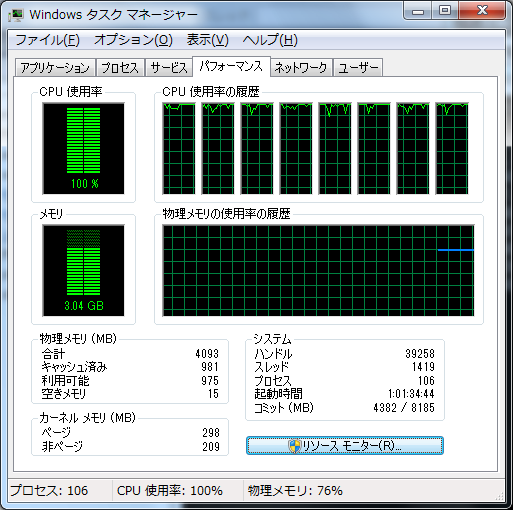
タスクマネージャ。8コア全部が100%に。こうやって見ると仕事してる感は出てるよね。
でもやっぱGPGPUのがおもしろいなぁ。